Big Data Research
Using Hadoop, Spark, and other tools
| Brock Palen | brockp@umich.edu |
| Seth Meyer | smeyer@umich.edu |
What is Hadoop?
Apache Hadoop is a framework for distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines by co-locating data and computation on each machine.
Flux Hadoop is the name of the trial ARC-TS Hadoop cluster.
Links and Tutorials
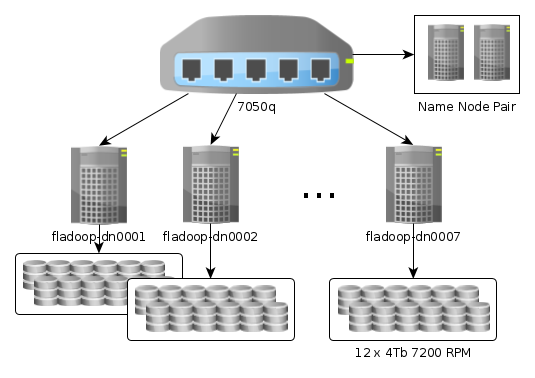
Flux Hadoop DocumentationHardware - Fladoop Architecture
Free UDACITY Hadoop/MapReduce Course Materials
Cloudera Quickstart VM
Avoid Writing MapReduce Code
- Lowest level of control in Hadoop
- Most difficult to work with
- Requires Java knowledge and lots of boilerplate code
Tools for Analysis
Alternatives to Writing MapReduce Code
The Hadoop File System (HDFS)
About HDFS
- Distributed and fault tolerant
- Requires use of HDFS-specific tools
- Looks like POSIX filesystems
- Optimized for read performance
Common HDFS Commands
# List files HDFS home directory
hdfs dfs -ls
hdfs dfs -ls /user/brockp
# Make a directory
hdfs dfs -mkdir directory
# Get full list of HDFS options
hdfs dfs -help
# Get help with single HDFS option, leave off the -
hdfs dfs -help ls
HDFS Practice
Create a directory in HDFS called arcdata and check its contents.
hdfs dfs -mkdir arcdata
hdfs dfs -ls arcdata
Moving to and from HDFS
get / put / distcp
# Get the sample data used later in the presentation
git clone https://bitbucket.org/umarcts/umarcts.bitbucket.org.git
cd umarcts.bitbucket.org/presentations
# Upload sample data for later use
hdfs dfs -mkdir -p warehouse/ngrams
hdfs dfs -put hadoop/ngrams.data .
hdfs dfs -put hadoop/ngrams.data ngrams.hive
# Download some data
hdfs dfs -get ngrams.hive .
Tool Examples
- Task: Find number of words per year that occur in only one volume
- Dataset: Google NGrams (specifically 1-grams)
- NGrams schema: word, year, occurrences, volumes
- NGrams dataset is tab separated
Hive
- SQL layer on Hadoop
- Supports most reading SQL queries
- Supports few writing SQL queries
- Fastest from idea to result
Starting Hive
# Start the interactive hive shell with default queue
hive
# Run a SQL script with Hive
hive -f path/to/script.sql
# specify a queue name
hive --hiveconf mapreduce.job.queuename=training
Creating a Table
-- Create the 'ngrams' table. For example, the word 'snake' appearred
-- 6449 times in 1755 volumes in the year 1943. This is represented by:
--
-- snake 1943 6449 1755
CREATE EXTERNAL TABLE brockp_ngrams
(ngram STRING,
year INT,
matches BIGINT,
volumes BIGINT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/user/brockp/warehouse/ngrams';
-- Load the data from HDFS into a Hive table. This must be done so that Hive
-- knows where to find the data.
LOAD DATA INPATH 'ngrams.hive' OVERWRITE INTO TABLE brockp_ngrams;
Querying the Data
-- Execute a query that finds all words that were only in a single volume in
-- any given year.
SELECT ngram, COUNT(ngram)
FROM ngrams
WHERE volumes = 1
GROUP BY ngram
ORDER BY ngram;
Query Result
snake 22
snaketail 10
Pig
- Similar to but more in-depth than SQL
- Better than SQL for complex transformations
- Slower than Hive
Running Pig code
# Open the pig shell on flux-login
pig
# Open the pig shell for local development
pig -x local
# Run the included warez/ngrams.pig script
cd hadoop-pres
hdfs dfs -put ngrams.data ngrams.data
pig -f warez/ngrams.pig
# Specify queue name
pig -Dmapreduce.job.queuename=training
Pig Code
-- Load the data.
data = LOAD 'ngrams.data' AS (ngram:chararray, year:int, matches:long,
volumes:long);
-- Running 'describe data' gives:
-- data: {ngram: chararray, year: int, matches: long, volumes: long}
filtered = FILTER data BY volumes == 1;
-- filtered: {ngram: chararray, year: int, matches: long, volumes: long}
grouped = GROUP filtered BY ngram;
-- grouped: {group: chararray, filtered: {(ngram: chararray, year: int,
-- matches: long, volumes: long)}}
answer = FOREACH grouped GENERATE group, SUM($1.volumes);
-- answer: {group: chararray, long}
ordered = ORDER answer BY $0 ASC;
-- ordered: {group: chararray, long}
DUMP ordered;
Pig Results
(snake,22)
(snaketail,10)
Hadoop Streaming: Python
- Map and reduce in Python
- Code reads from STDIN and writes to STDOUT
- Slow due to interpreter start-up overhead
- Slow due to short task lives - JIT does not help
Mapper
#!/usr/bin/env python3
import fileinput
for line in fileinput.input():
split = line.split("\t")
if int(split[3]) == 1:
print('\t'.join([split[0], '1']))
Mapper Continued
- Iterate over STDIN with fileinput.
- Split each line.
- Check if the ngram is only in one volume.
- If so, print out the year and a '1' as a tab-separated key-value pair.
Reducer
#!/usr/bin/env python3
import fileinput
year_count = dict()
for line in fileinput.input():
tmp = line.split('\t')
if tmp[0] not in year_count.keys():
year_count[tmp[0]] = 0
year_count[tmp[0]] = year_count[tmp[0]] + int(tmp[1])
for year in sorted(year_count.keys()):
print('\t'.join([year, str(year_count[year])]))
Reducer Continued
- Sum the amount of ngrams that only appear in one volume by year
- Print the sorted result
Sumbitting Python
# Run Python on a Hadoop cluster
yarn jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
-Dmapreduce.job.queuename=training \
-input ngrams.data -output ngrams-output \
-mapper warez/map.py -reducer warez/reduce.py \
-file warez/map.py -file warez/reduce.py
# Look at the output from the job
hdfs dfs -cat ngrams-output/part*
# Run locally for testing
cat ngrams.data | python3 warez/map.py | python3 warez/reduce.py
snake 22
snaketail 10
Spark
- Spark supports Scala, Java, and Python
- Packaging Scala and Java for job submission is complicated
- Spark examples will be shown in Python
- PySpark, the Python API, is slower than the Scala/Java API
PySpark Shell and Submission
# Open the interactive PySpark shell
pyspark --master yarn-client
# Open the interactive PySpark shell locally
pyspark --master local
# Submit a PySpark job to the cluster
spark-submit --master yarn-client \
--num-executors 2 \
--executor-memory 3g \
warez/ngrams-spark.py
PySpark code
from pyspark.conf import SparkConf
from pyspark.context import SparkContext
conf = SparkConf().setAppName('NGrams')
sc = SparkContext(conf=conf)
ngrams = sc.textFile("ngrams.data")
columns = ngrams.map(lambda line: line.split("\t"))
filtered = columns.filter(lambda arr: int(arr[3]) == 1)
reducable = filtered.map(lambda arr: (arr[0], 1))
answer = reducable.reduceByKey(lambda a, b: a + b)
for k, v in answer.collect():
print('\t'.join([k, str(v)]))
Spark SQL with Hive
- Spark SQL gives Data Frames and SQL support
- Spark auto imports tables from Hive
PySpark SQL code
ans = spark.sql("SELECT ngram, COUNT(ngram) FROM ngrams \
WHERE volumes=1 GROUP BY ngram ORDER BY ngram")
ans.show()
# ans is really a dataframe and we can mix the syntax
ans.count()
ans.printSchema()
ans.filter(ans['ngram'] == 'snake').show()
Choosing a tool and language
- If you can use a tool you're already familiar with, do
- Working on structured data? Use Hive or Pig
- There is probably already an Apache tool to do what you want
Testing Locally
You can test both Pig and Spark locally if you have them installed. In addition, there is a Dockerfile here that provides a pre-built environment for testing Pig and Spark if you are a Docker user.
Contact Info
Going Big
# start hive drop old ngrams and replace with full size copy on cluster
# note lack of importing data, if data already exists its left in place
# There are also ways to make these data even faster contact for help
DROP TABLE ngrams;
CREATE EXTERNAL TABLE ngrams
( ngram STRING,
year INT,
count BIGINT,
volumes BIGINT )
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION '/var/ngrams';
Going Big Ctd.
# Large data makes more partitions
# Parallelism is limited to the extent of these blocks
# 23GB -- 396 partitions
# 1,201,784,959 Rows
SELECT year, COUNT(ngram)
FROM ngrams
WHERE volumes = 1
GROUP BY year;